
POS データ 見える化 (エクセル編)
販売系の根本データ、POSデータを活用してさまざまな分析を行います。
目次
データ
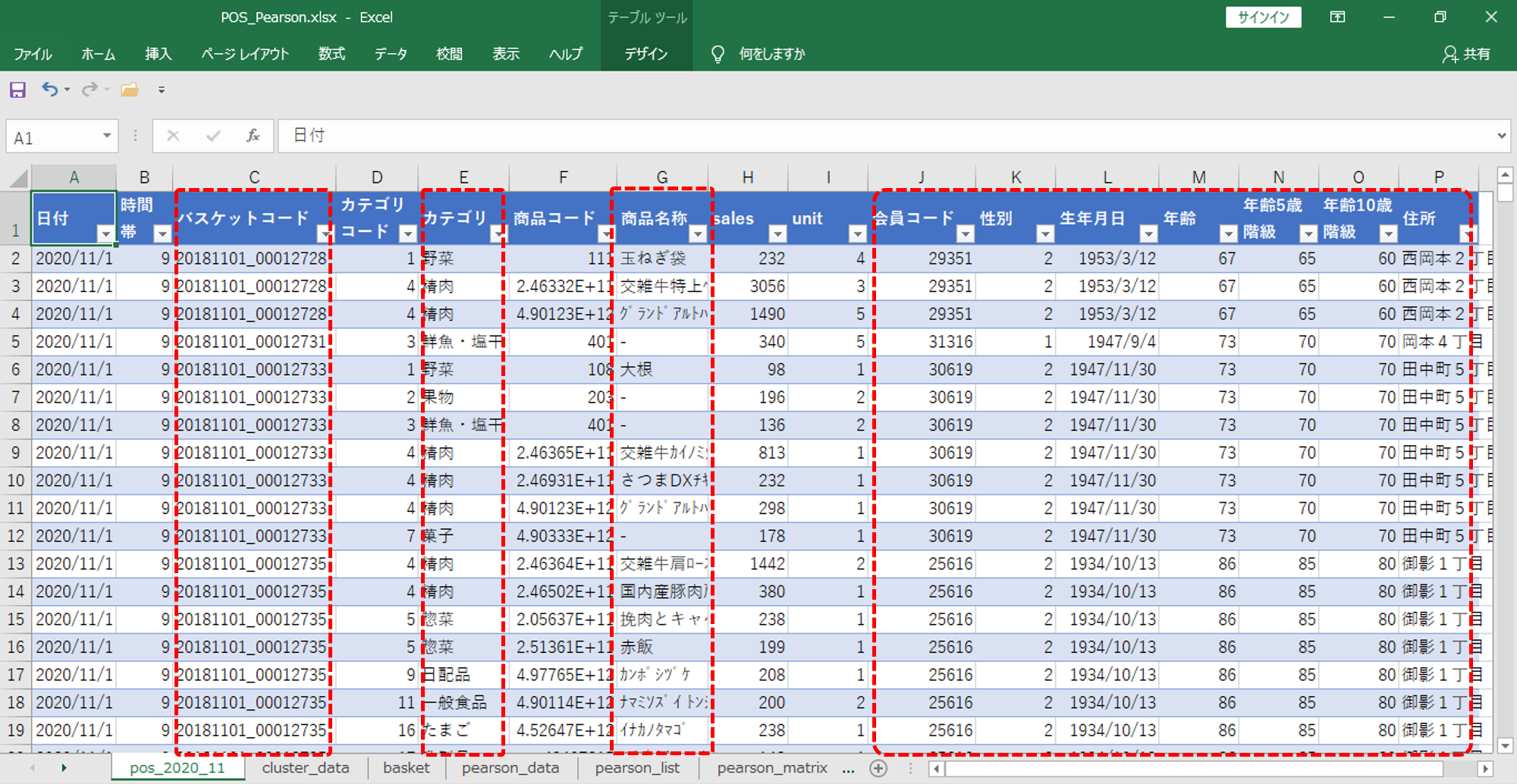
データ期間=2020年11月
行数=約15万行
データは完全なダミーです。
・バスケットコードを作成します。(統計解析で使用します)
レジの1会計 (合計現計) ごとに個別の値 (ユニーク) になるように作成します。具体的には、「日付」+「例番号」+「時刻」のような組み合わせで作成できます。
・カテゴリ名や商品名
概ねPOSデータのカテゴリや商品は、それらのコードのみ記載されています。カテゴリマスタや商品マスタとマージ (結合) してカテゴリ名、商品名を表示しておくと結果がみやすくなります。
・会員の属性
会員マスタとマージ (結合) して会員の属性をくっつけます。
会員別売上データとの違い
・POSデータには取引時刻があります。
・POSデータには商品コードがあります。
誰が、いつ、何を、何個、いくらの売価で購入したのかを知ることができます。
分析例
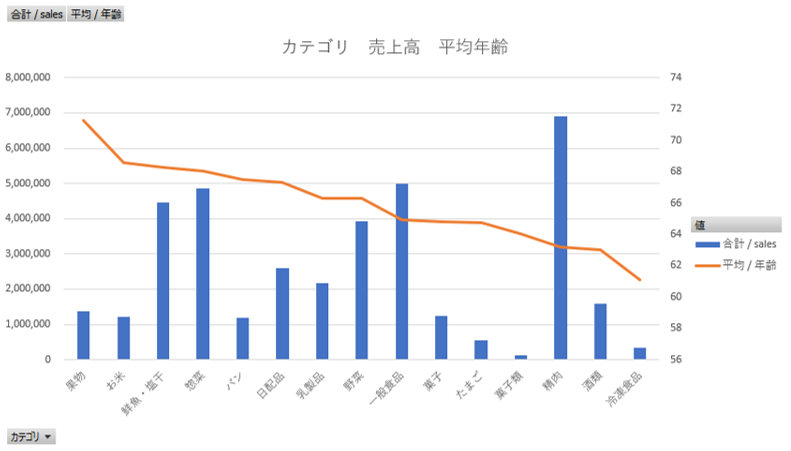
年齢によりカテゴリの好みがあるように見える。
<軸>
カテゴリ(平均年齢降順)
<系列>
値
<メジャー>
売上高、年齢 (平均)
<グラフ>
組み合わせ (縦棒、折れ線)
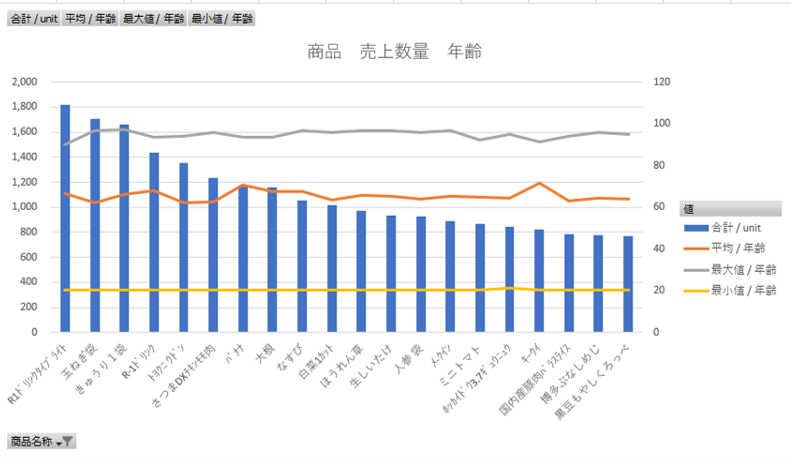
商品ごとに年齢による好みがあるのかどうか。
<軸>
商品 (売上数量降順)、売上数量(上位20位フィルター)
<系列>
値
<メジャー>
売上数量、年齢 (平均、最大値、最小値)
<グラフ>
組み合わせ (縦棒、折れ線)
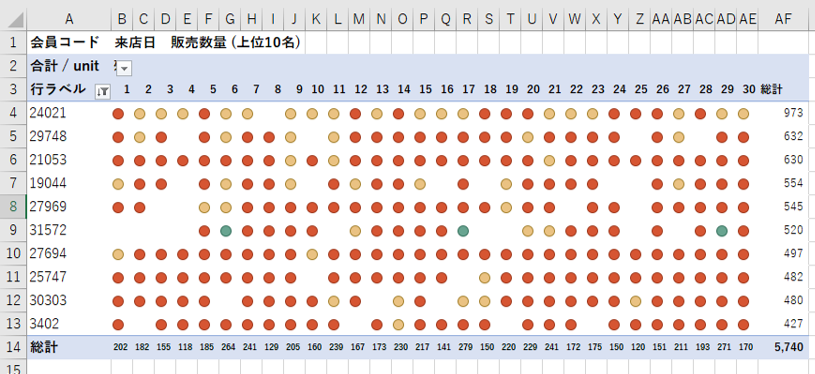
顧客ごとの来店パタンに翌朝があるのかどうか。
<軸>
顧客コード (販売数量上位10位フィルター)
<系列>
値
<メジャー>
売上数量、会員コード (個数)
<色>
販売数量

ピボットを組み合わせます。
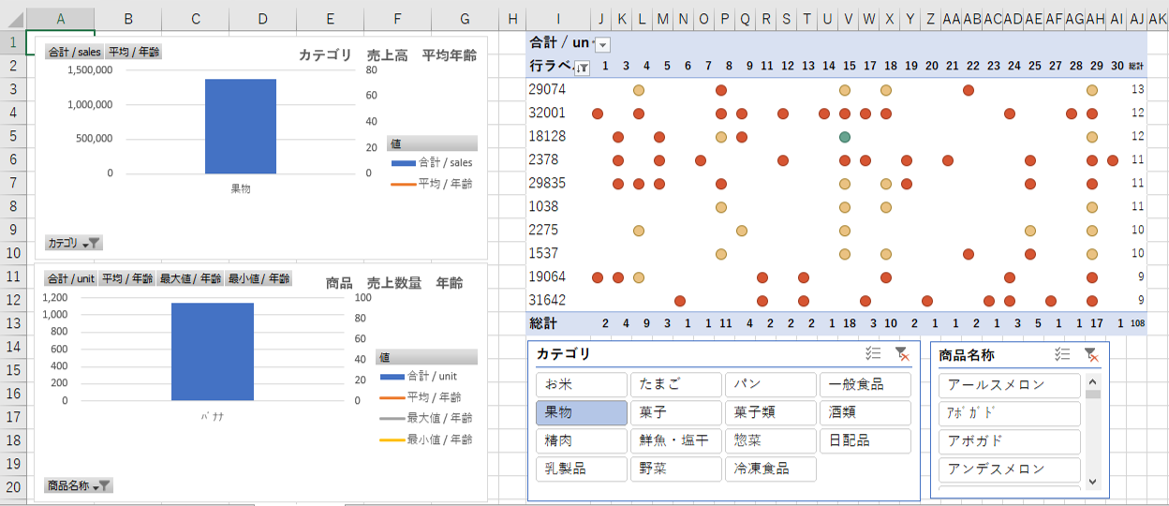
・果物を選択します。
・「バナナ」を選択します。
バナナを購入した会員コードの来店パタンを見える化できます。
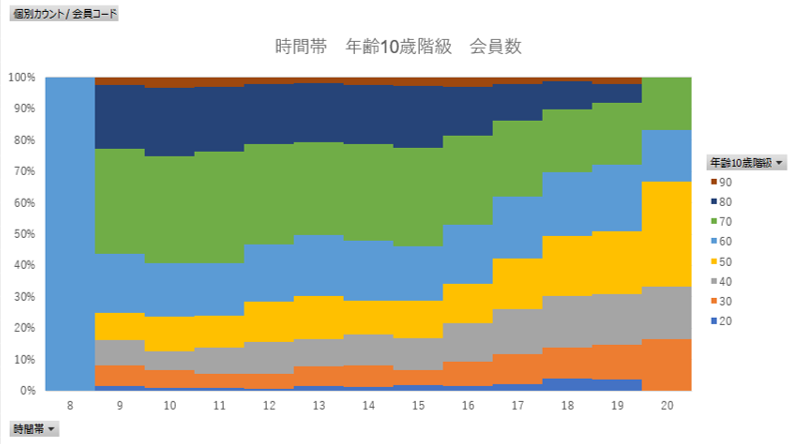
午前中はご高齢者のお客様が多い。
<軸>
時間帯
<系列>
年齢10歳階級
<メジャー>
顧客コード (個数の累計)
<グラフ>
100%縦棒

ピボットを組み合わせます。

・時間帯、年代でフィルターします。
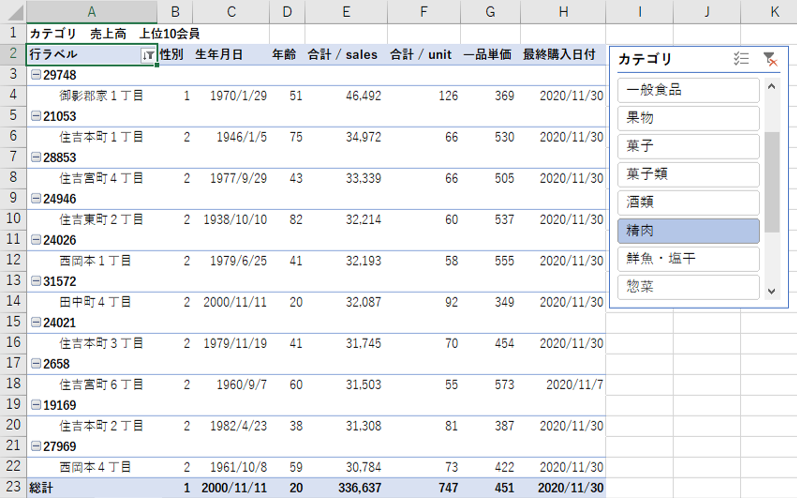
いわゆる上得意様は具体的に誰か。
<行>
会員コード、住所
<列>
値
<メジャー>
性別、生年月日、年齢、売上、数量、一品単価、日付 (最大値)
<グラフ>
テーブル
住所マスタとリレーションシップ
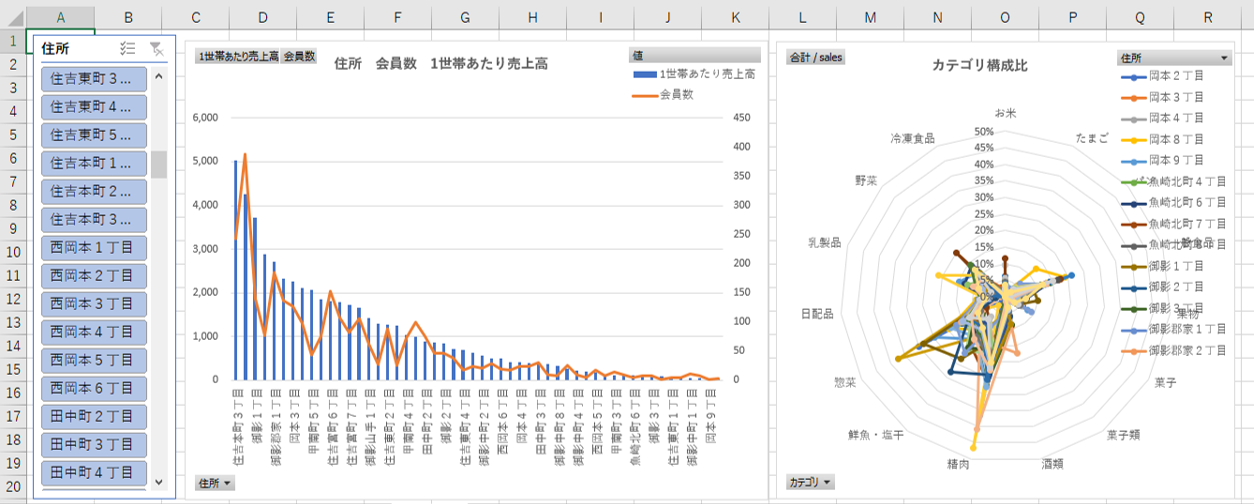
住所マスタとリレーションシップします。

住所をフィルターします。
マッピング
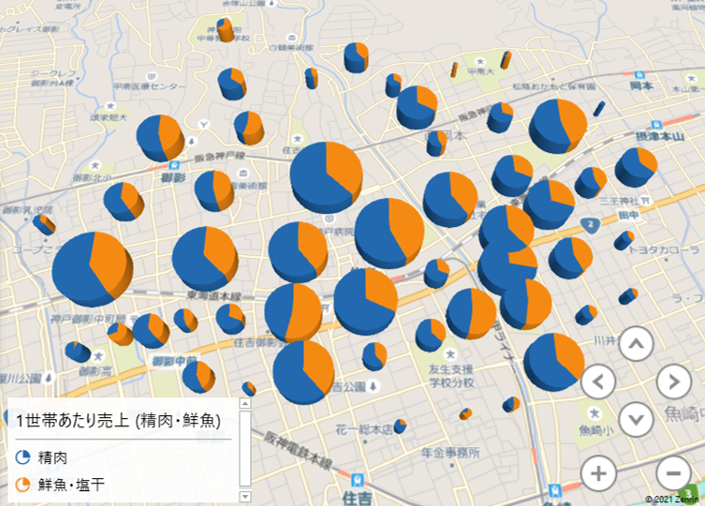
<サイズ>
1世帯あたり売上高
<マップ>
バブル
<サイズ>
数量
<マップ>
棒
クラスター

| 集計粒度 | 会員コード |
| 値 | カテゴリの売上高の割合 |
| クラスター形成方法 | 階層的 |
| クラスター数 | デンドログラムの8でカット |
各会員がどのカテゴリをより多く購入しているかによるクラスターを形成しています。
飲食データでいうと、ビール党、ワイン党、ハイボール党、しょうちゅう党のようなクラスター化です。
>クラスター分析(第1回) 好きと苦手の境界線 (data-analyzer.net)
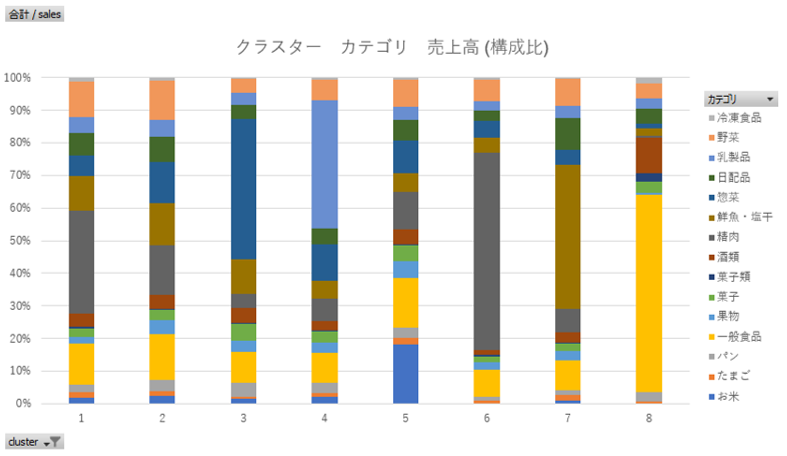
購入する比率が高いカテゴリでクラスターを形成。精肉、鮮魚、一般食など購入の傾向でクラスタリングできる。
<軸>
クラスター
<系列>
カテゴリ
<メジャー>
売上高
<グラフ>
100%積み上げ縦棒
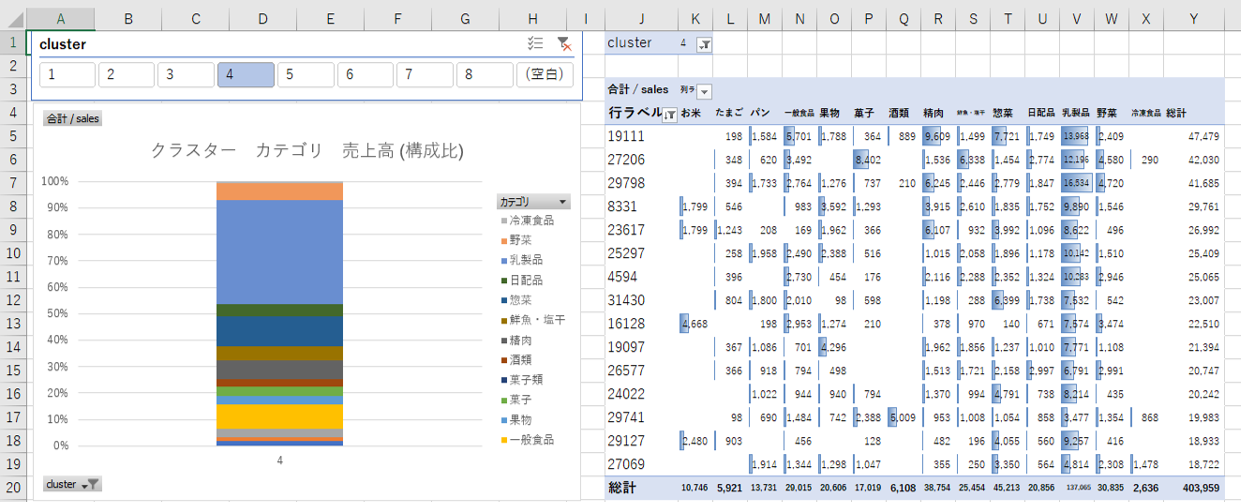
・フィルターで「乳製品」の売上高構成比が高いクラスターを選択します。

各クラスターの特徴、クラスターごとにどのカテゴリーの売上構成比が高いのか。。
<軸>
クラスター
<系列>
なし
<メジャー>
クラスター内のカテゴリ売上高構成比 (クラスター内のカテゴリ売上高÷クラスターの合計売上高)
<グラフ>
縦棒
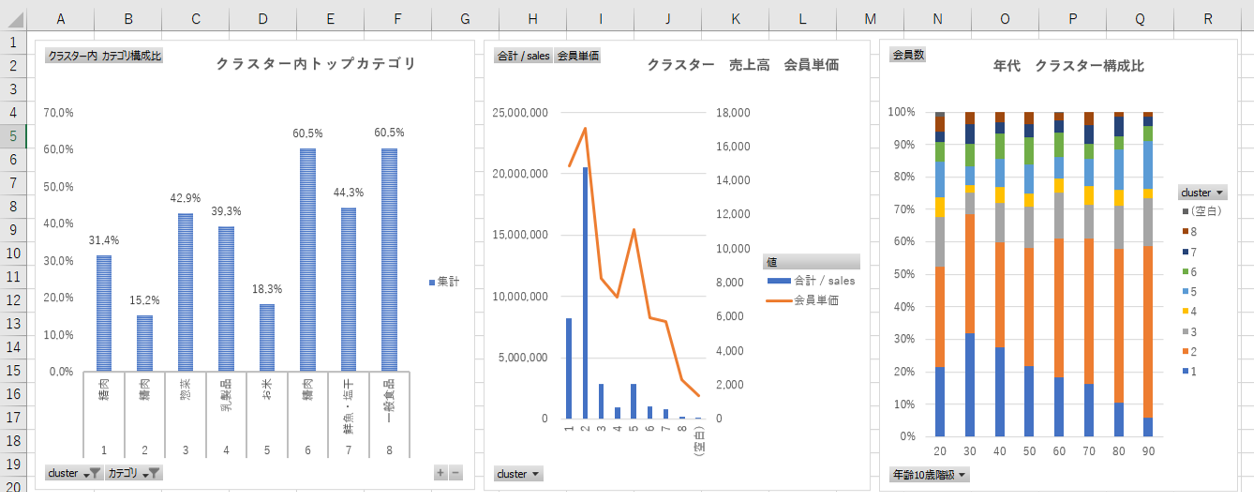
クラスター2、各カテゴリーをバランスよく購入するクラスターの売上高、会員単価が高い。
Pearson 相関
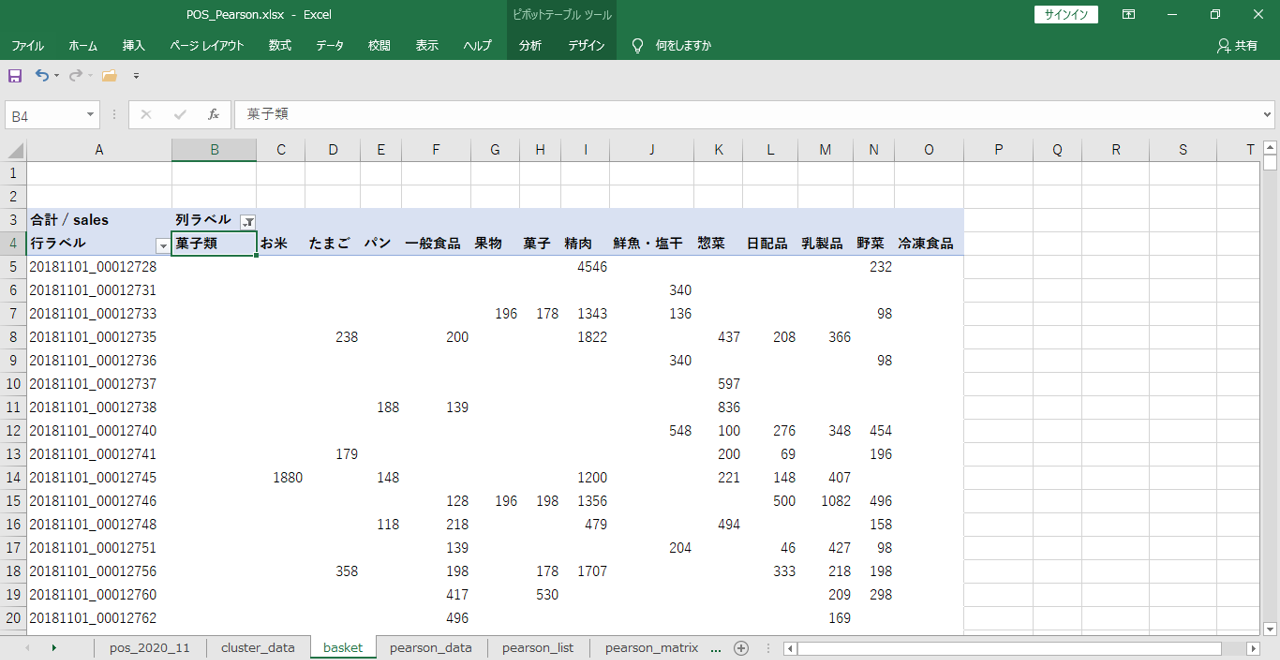
| 集計粒度 | バスケットコード |
| 相関 | カテゴリ |
カテゴリどうしの組み合わせの良さをバスケットコードを粒度に計算します。
>Pearson 相関 エクセル編 (data-analyzer.net)
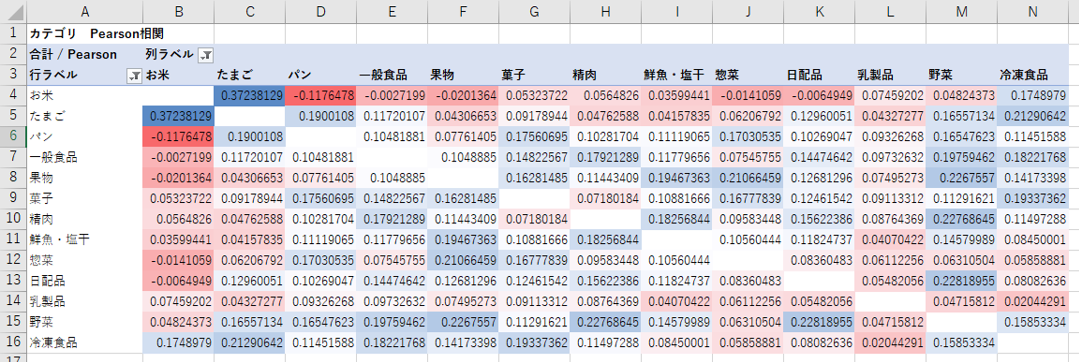
買い物カゴの中、どのカテゴリの組み合わせで売れているのか。
<行>
カテゴリ
<列>
カテゴリ
<メジャー>
Pearson相関係数
<グラフ>
テーブル
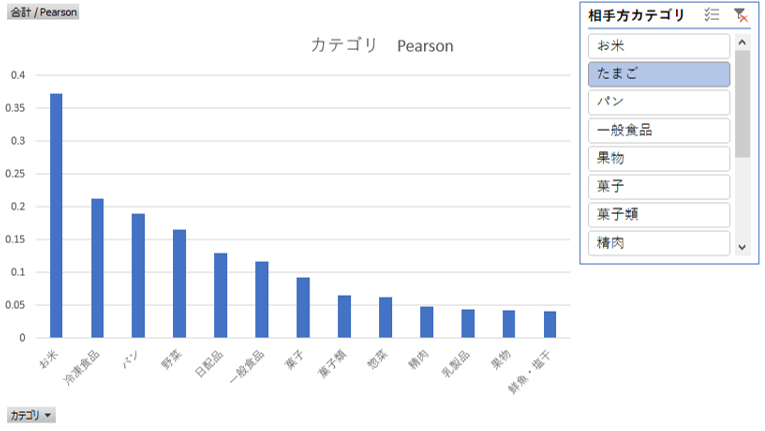
<軸>
カテゴリ
<系列>
値
<メジャー>
Pearson相関係数
<グラフ>
縦棒