
テキストデータ 見える化 (エクセル編)
テキストマイニングツールが得意なこと。エクセルが得意なこと。それぞれの得意技を合体させてテキストマイニングツールでは表現が難しい値をエクセルで見える化します。
目次
テキストマイニング
データ
分析対象テキストは、ある飲料品のクチコミです。クチコミごとに「年代」「性別」「都道府県」製品にたいする「評価ポイント」 (星の数) がついています。
テキストマイニングツールは「KH coder」を使用します。

抽出語対応分析結果
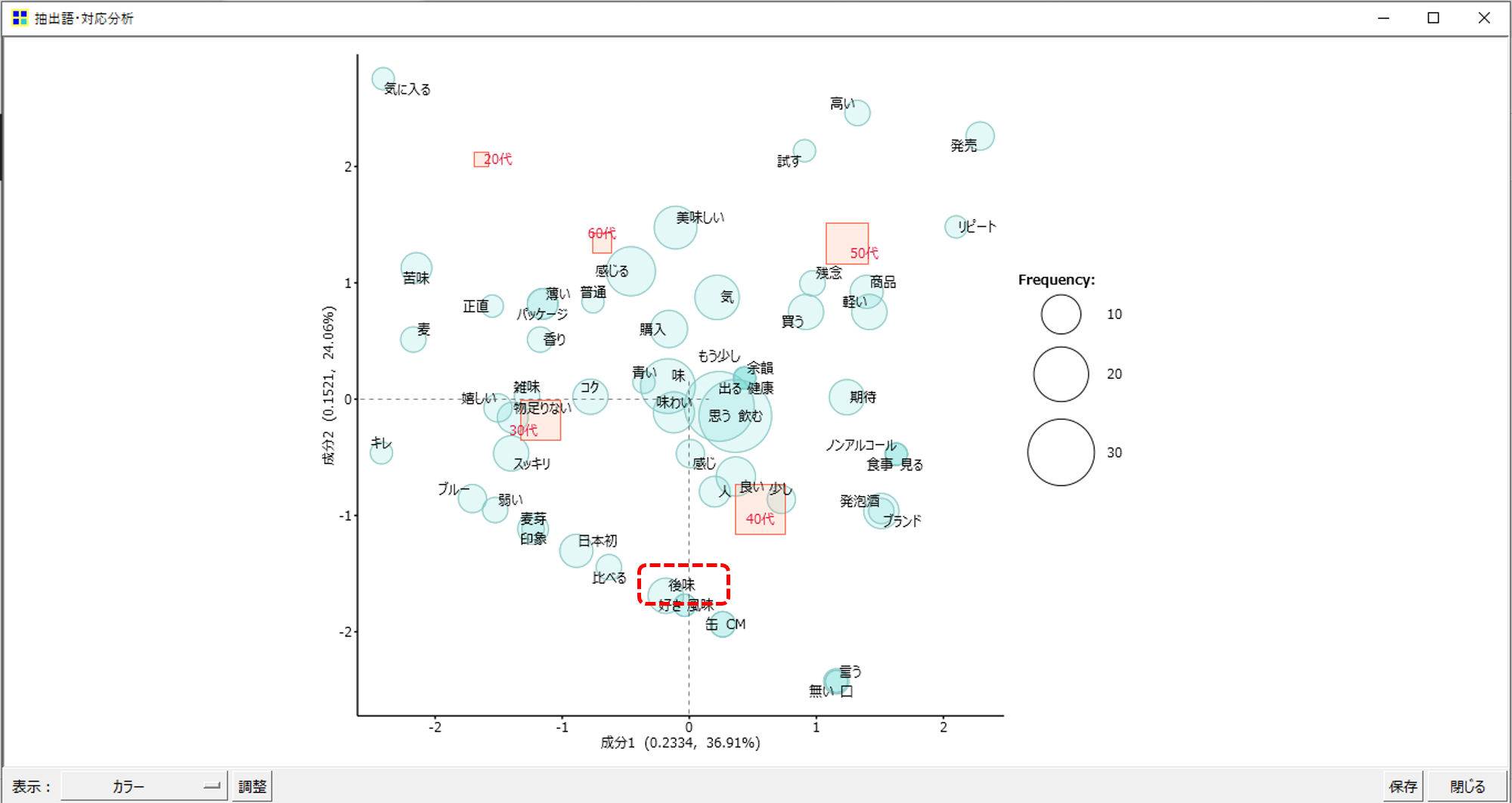
テキストマイニングの代表的な分析、対応分析結果です。
<概略>
・縦横のの各スケールのゼロが交差する原点付近 (チャートの中央付近) に表示されている「語」は20代~60代の各年代に共通して出現している「語」です。
・赤い四角の近辺に表示される「語」はその年代に特徴的にあらわれる「語」だといえます。
例えば、
・「物足りない」は30代の特徴語
・「美味しい」は60代の特徴語
・「後味」は30代~40代の特徴語
このように見てとれます。
では、具体的に「後味」がどの年代に何回出現しているのか?あるいは、年代・性別ごとの出現は?
対応分析からこのような質問に答えるのは難しいのです。テキストマイニングツールというのが、大量の文書を単手順で、全体を俯瞰できるように見える化することを得意にしているからです。
共起ネットワーク
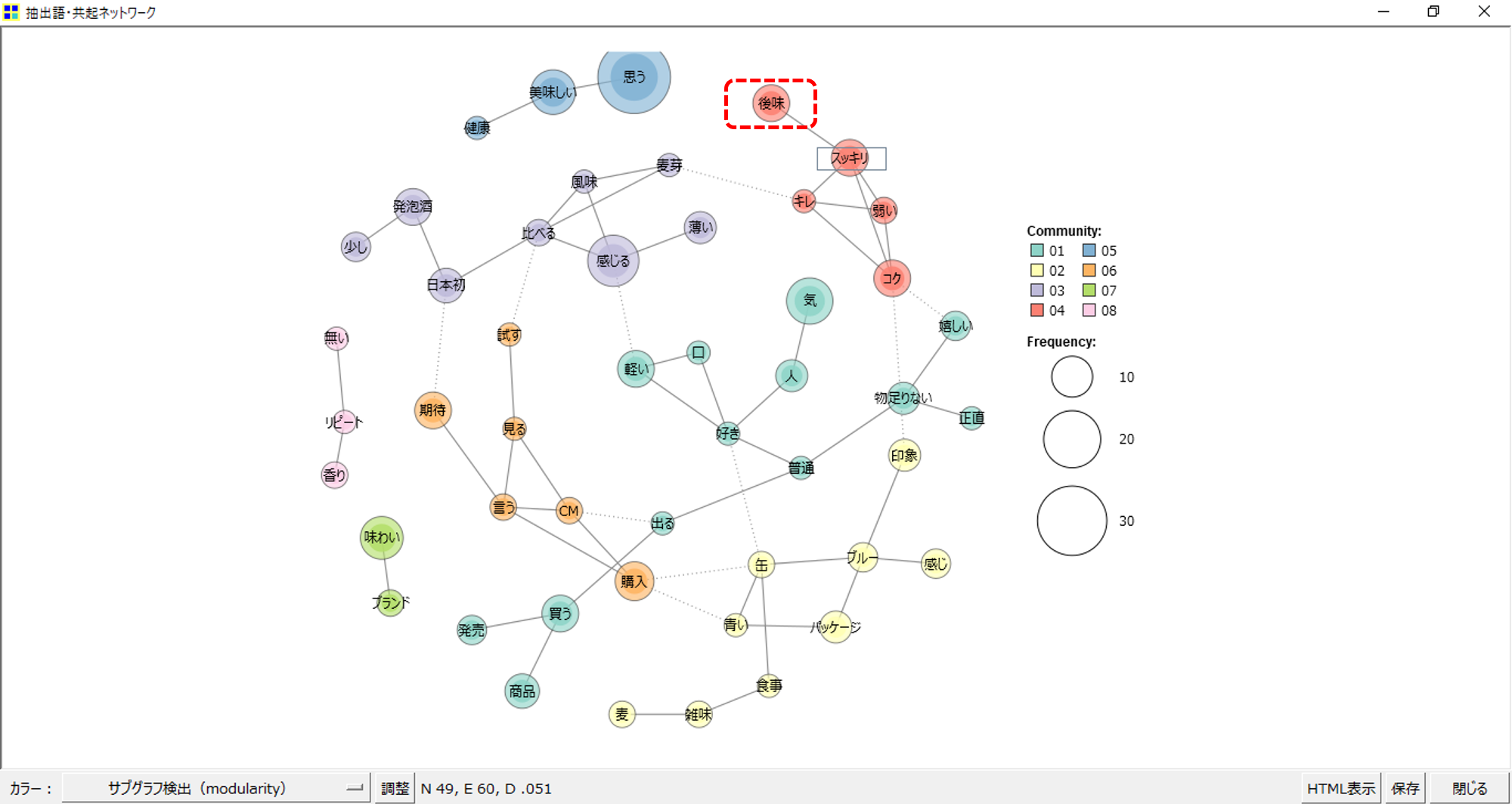
共起ネットワークで「後味」と共起している「語」の関係をみることができます。
しかし、「後味」と「スッキリ」の出現回数や共起の回数などの具体的な数値は見えません。

共起の数値は「関連語検索」で見ることができます。JACCARDをグラフで見える化するとか、検索する「語」を見える化したリストから選択できるとか。
見える化の構造
ツールの役割
<KH coder>
・「段」から「文」をとりだす。
・「語」 & 「品詞」をとりだす。
・「語」が「文」に出現する回数をとりだす。
<エクセル>
・「語」の出現回数を集計する。
・集計結果を見える化する。
KH coder から取り出すデータ
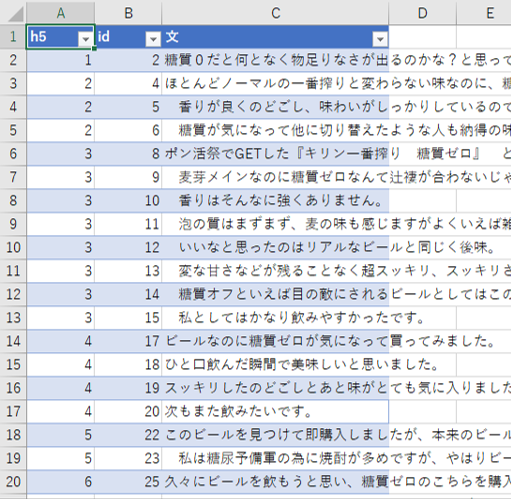
データ:文
・「ツール」
・「文書」
(バージョンにより「プロジェクト」→「エクスポート」)
・「文書×抽出語」表の出力
・「不定長 CSV」
「h5」=段のID
「id」=文のID
各ID付きの文をとりだします。
この取り出し方では「文」に含まれる「抽出語」が活用形に変換されます。
・「ツール」
・「テキストファイルの変形」
・「HTMLからCSVに変換」
こちらから取り出した「文」へ「h5」「id」をくっつけます。
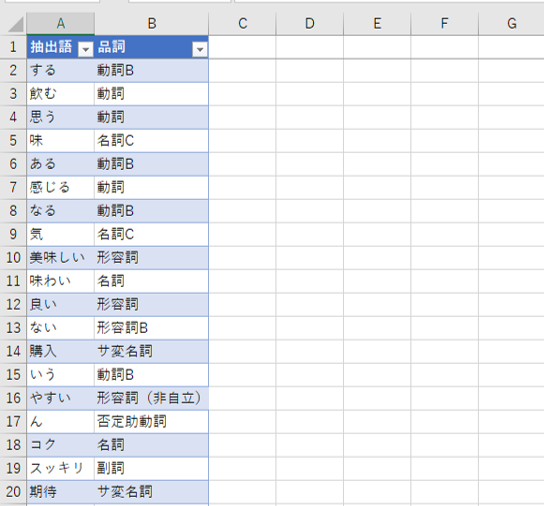
データ:抽出語
・「ツール」
・「抽出語」
・「抽出語リスト (EXCEL出力)」
・「1列」
品詞付きの抽出語をとりだします。
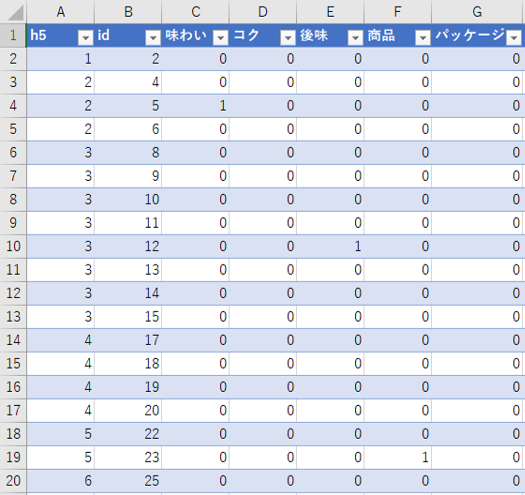
データ:文×抽出語
・「ツール」
・「文書」
(バージョンにより「プロジェクト」→「エクスポート」)
・「文書×抽出語」表の出力
・「CSV」
「h5」=段のID
「id」=文のID
各ID付きで「語」の出現回数をとりだします。

データ:テキスト
「h5」=段のID
各種外部変数がついています。
KH coder へロードしたテキストデータです。
データの組み合わせ
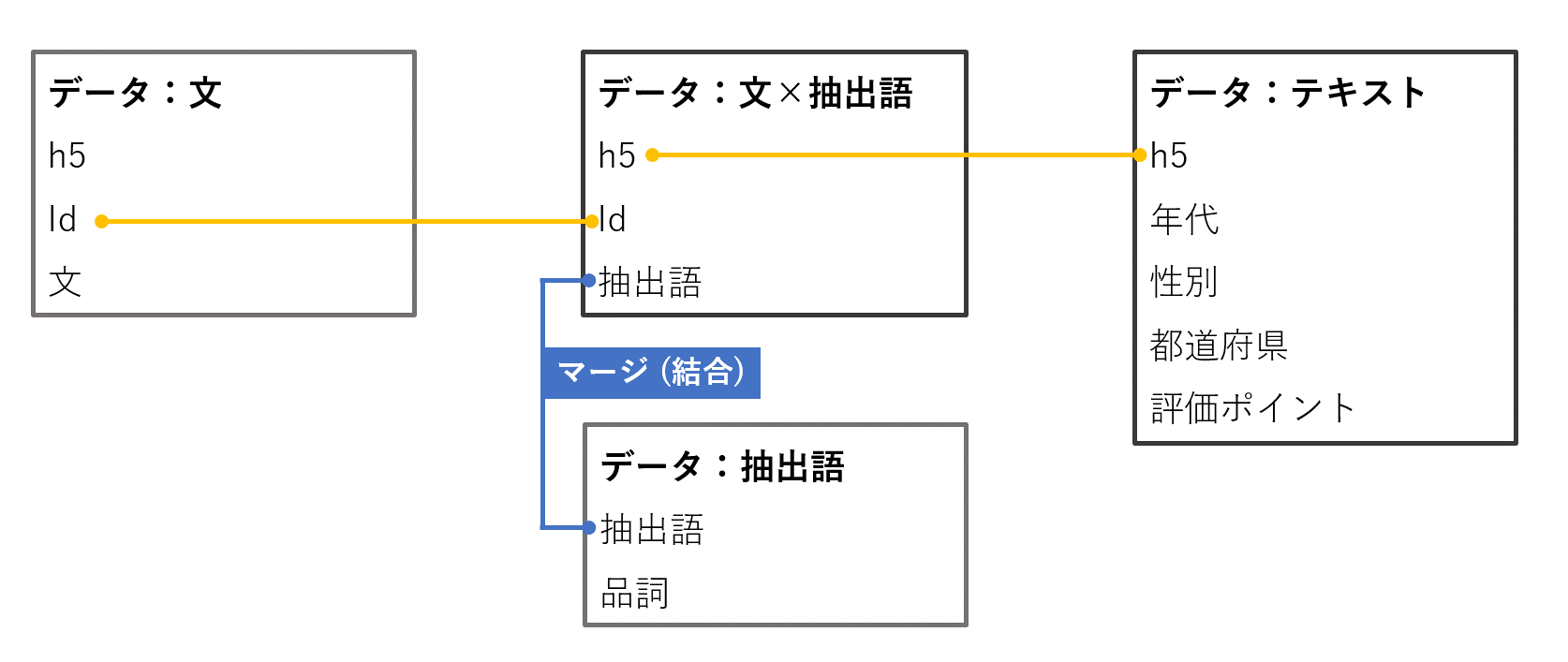
・「文×抽出語」へ「抽出語」の「品詞」をくっつけます。
・「文×抽出語」と「テキスト」を「h5」でリレーションし、「抽出語」と各外部変数を関連付けます。
・「文×抽出語」と「文」を「id」でリレーションし、「抽出語」と「文」を関連付けます。
エクセルで集計・見える化
属性
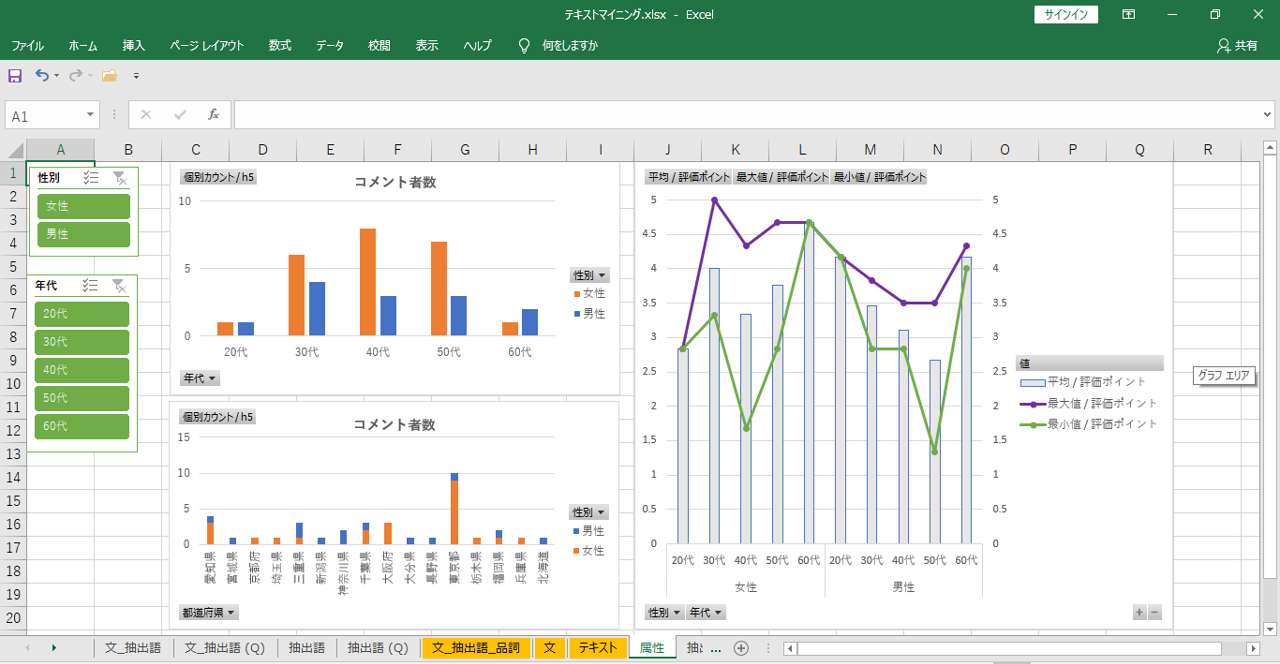
コメント者の属性は「KH coder」からデータをとりだすことなくデータ「テキスト」だけで見える化できます。
「年代」「性別」「都道府県」「評価ポイント」などの外部編集を集計します。
語の出現回数 (文)
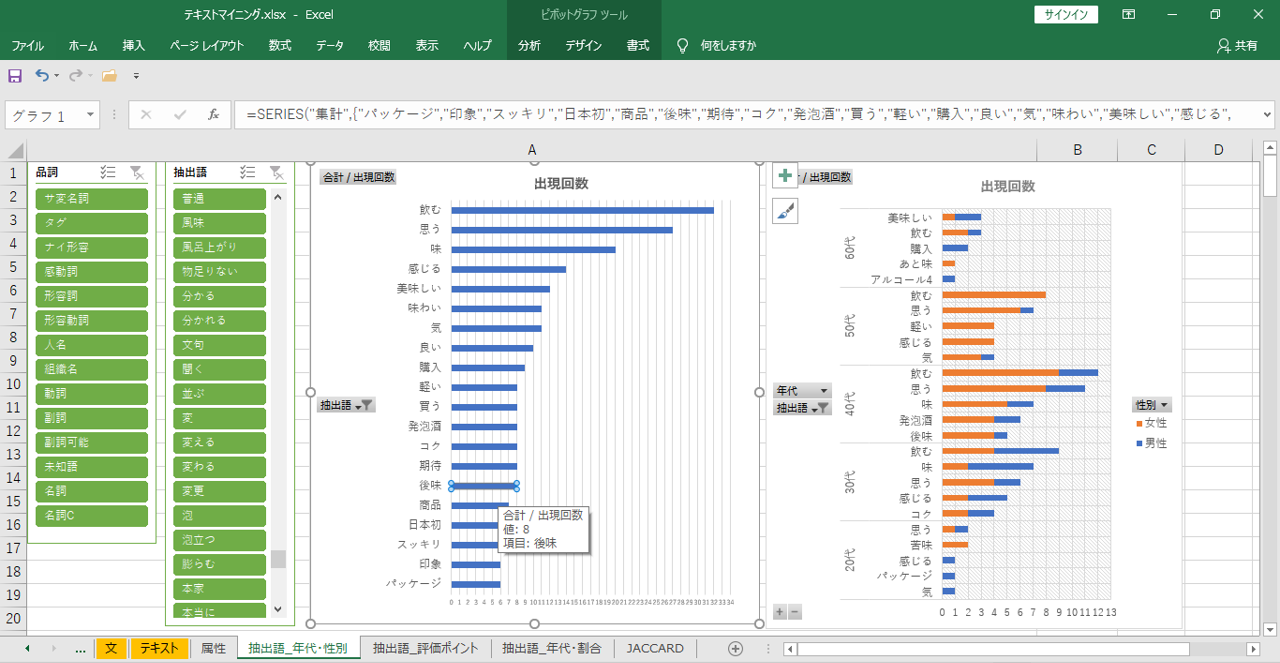
「年代」・「性別」ごとの「語」の出現回数を集計して見える化します。
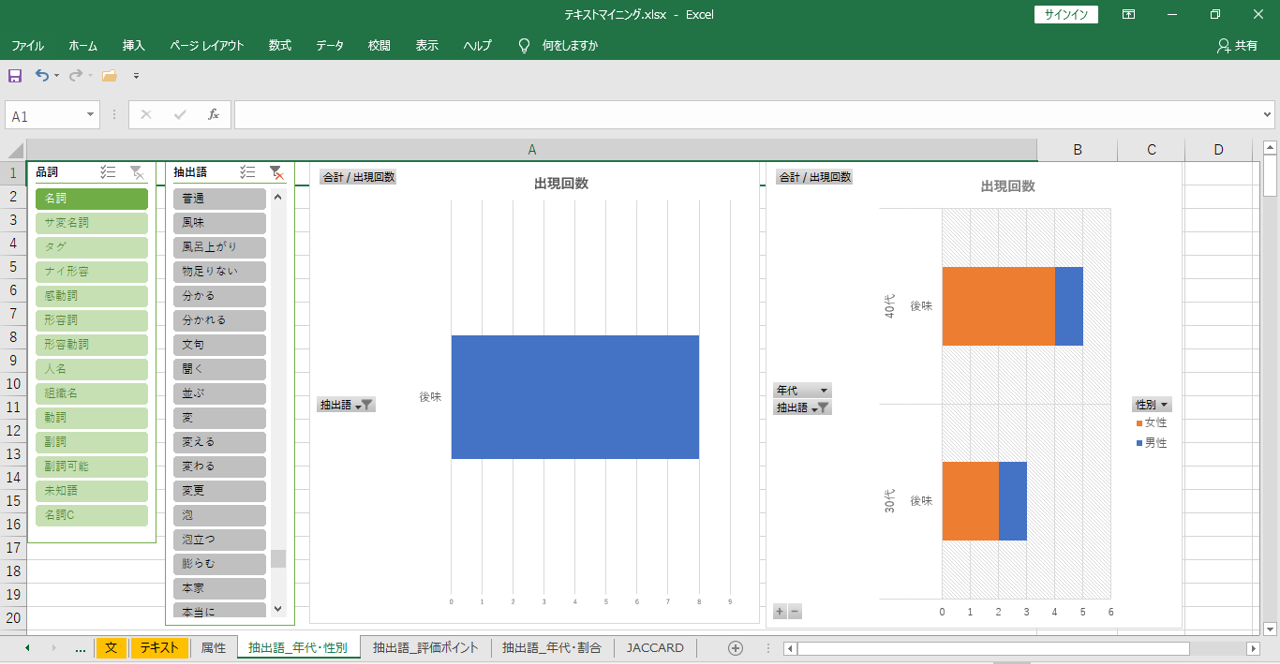
「後味」をフィルターで選択します。
・「年代」と「性別」ごとの出現回数を示すことができます。
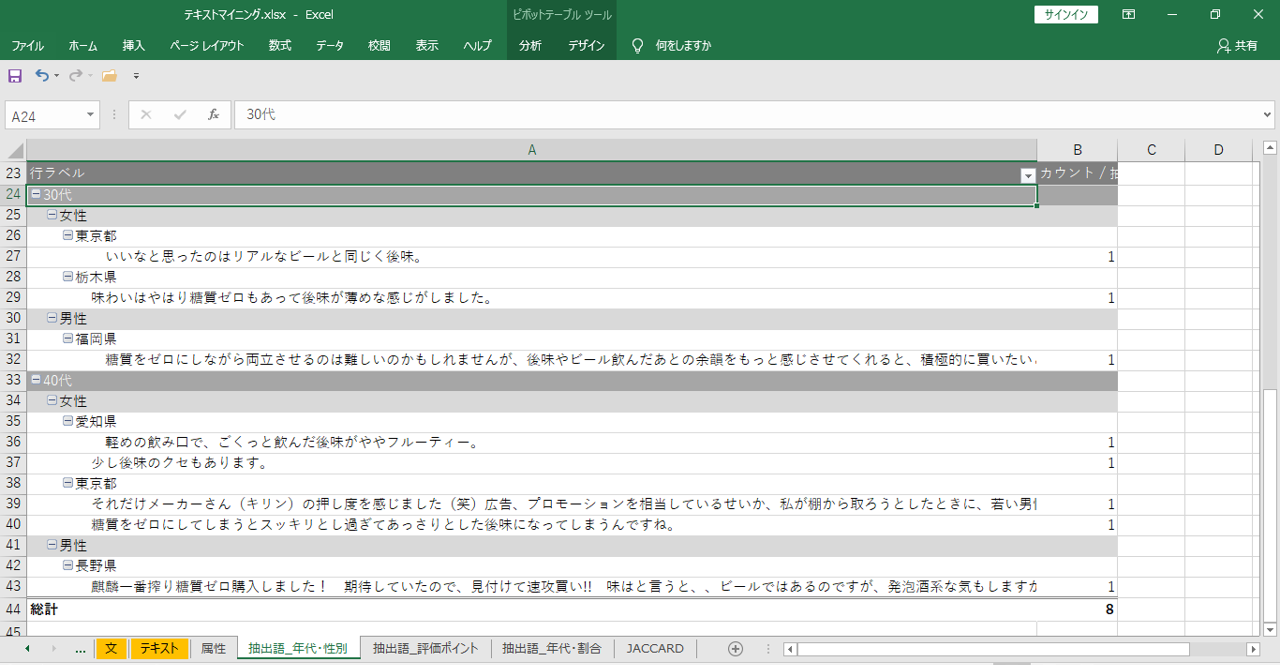
「語」をフィルターで選択すると、その「語」が出現する「文」を抽出して表示します。
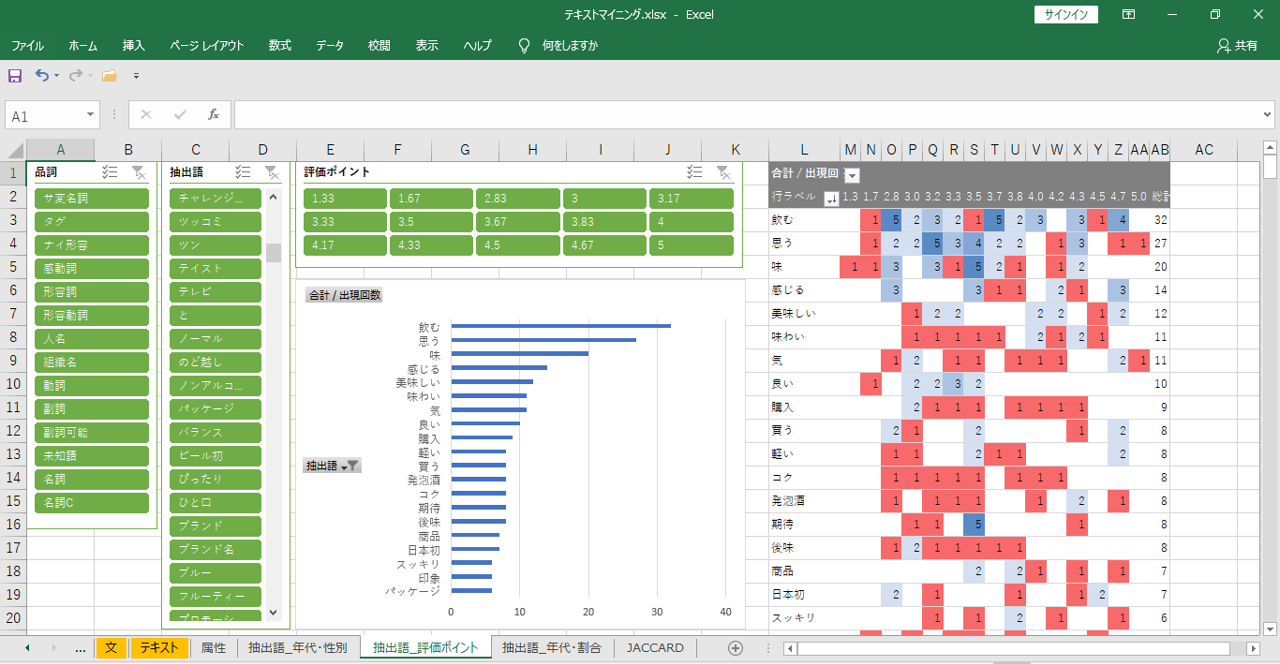
「評価ポイント」と「語」の出現パタンを見える化します。
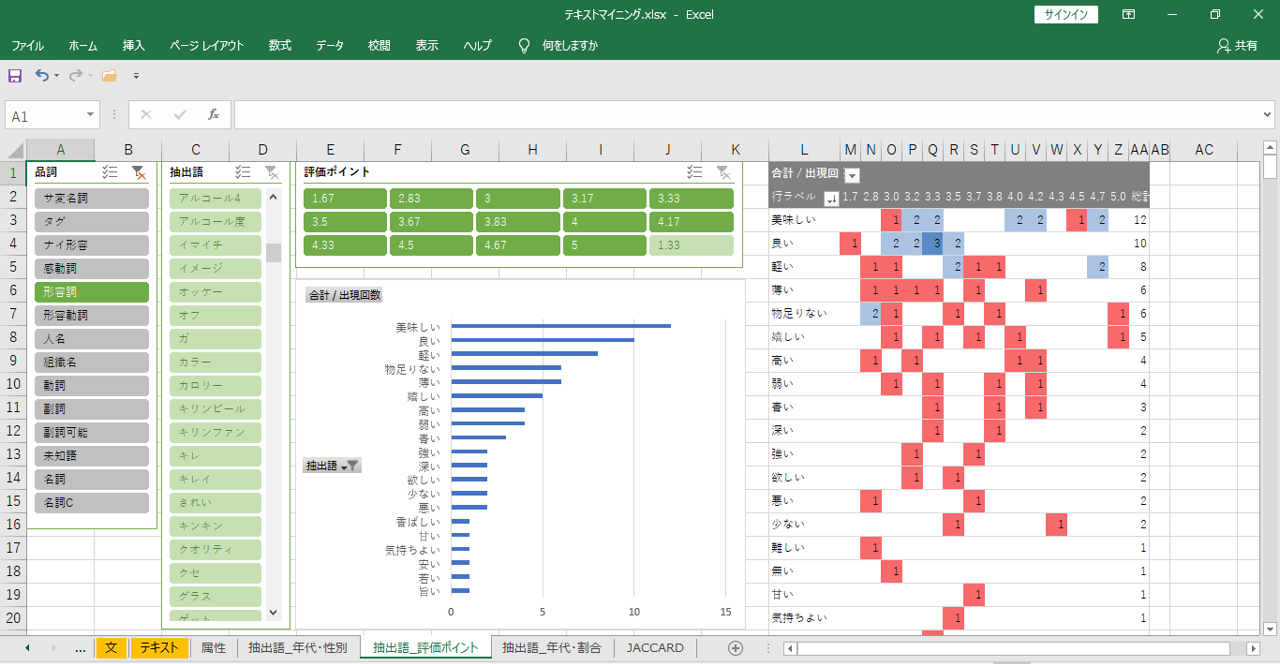
フィルターで形容詞を選択します。「形容詞」「形容動詞」「副詞」は製品の評価をあらわす「語」が含まれていることがおおくあります。「名詞」「サ変名詞」「名詞C」には、興味・関心があることについての「語」が含まれていることがあります。
語の出現回数 (段)
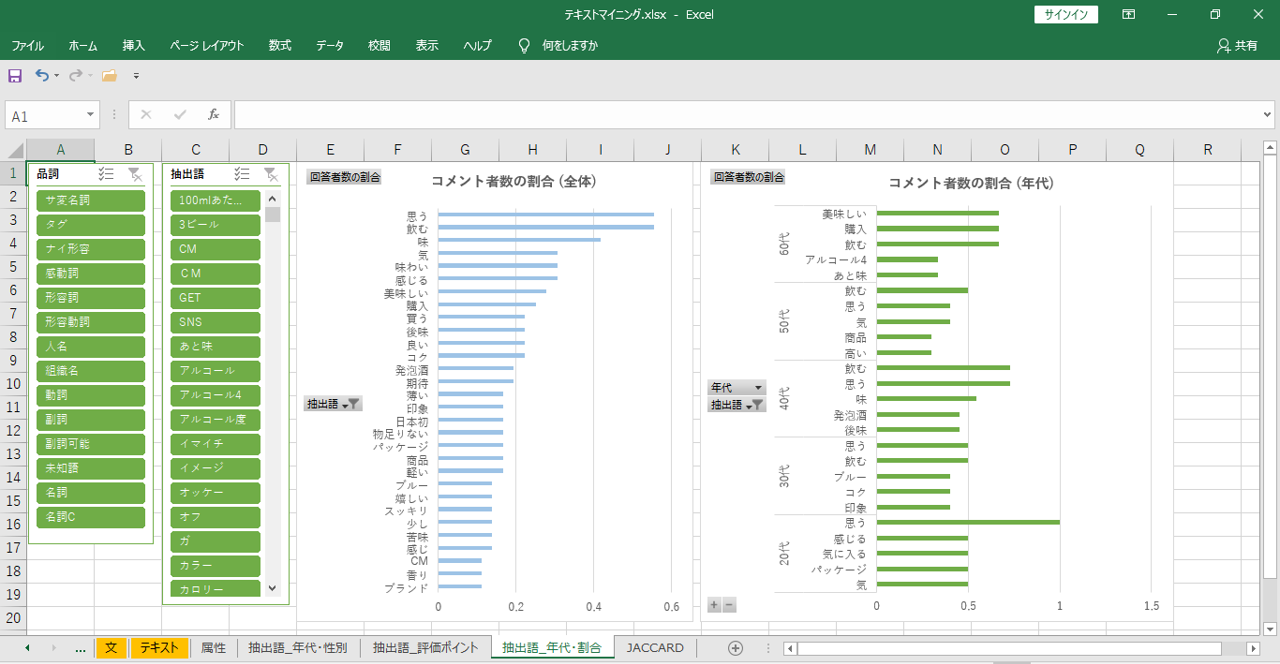
・分子=「語」が出現する重複しない「段」数
・分母=総「段」数=コメント者数合計
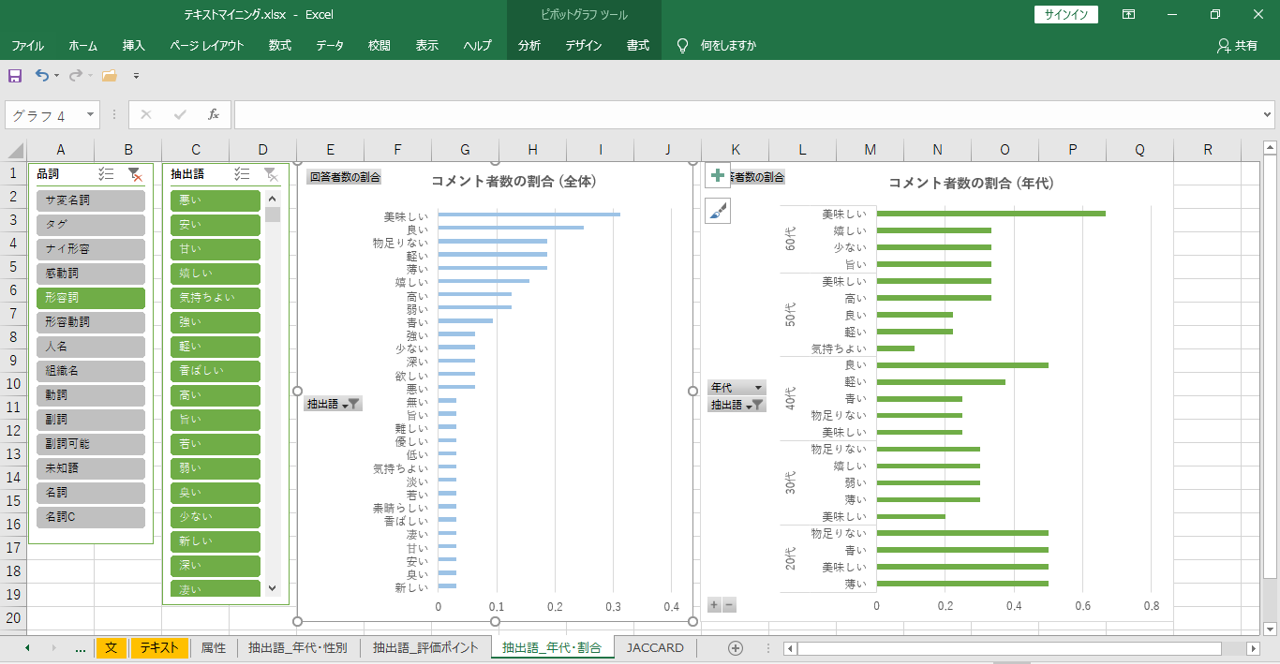
「美味しい」は全体の約3割、60代では三分の二に出現します。
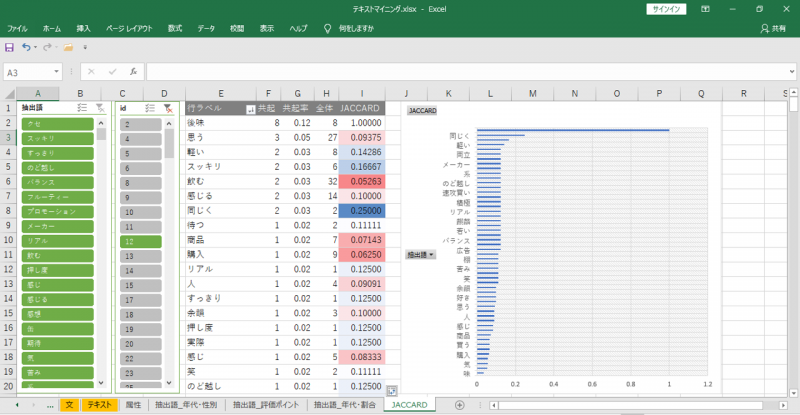
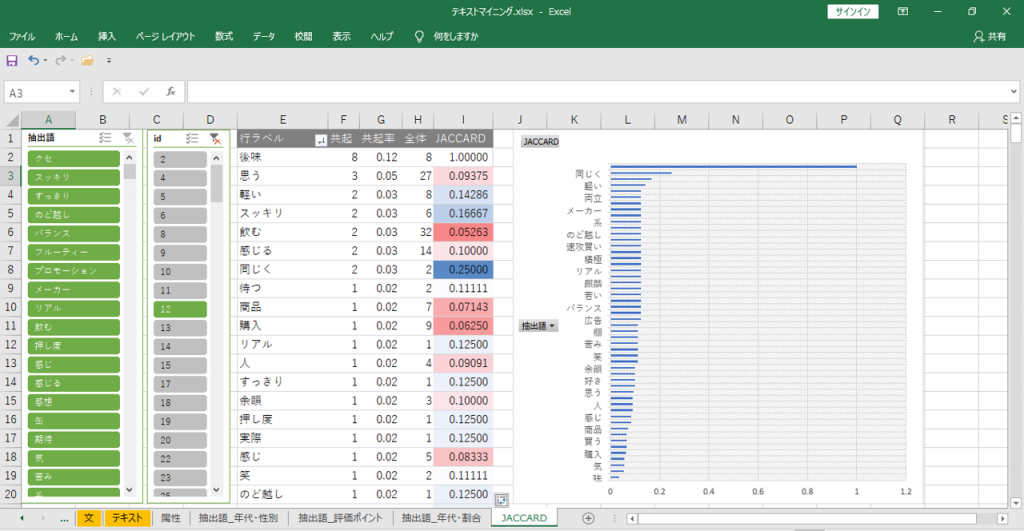
JACCARD
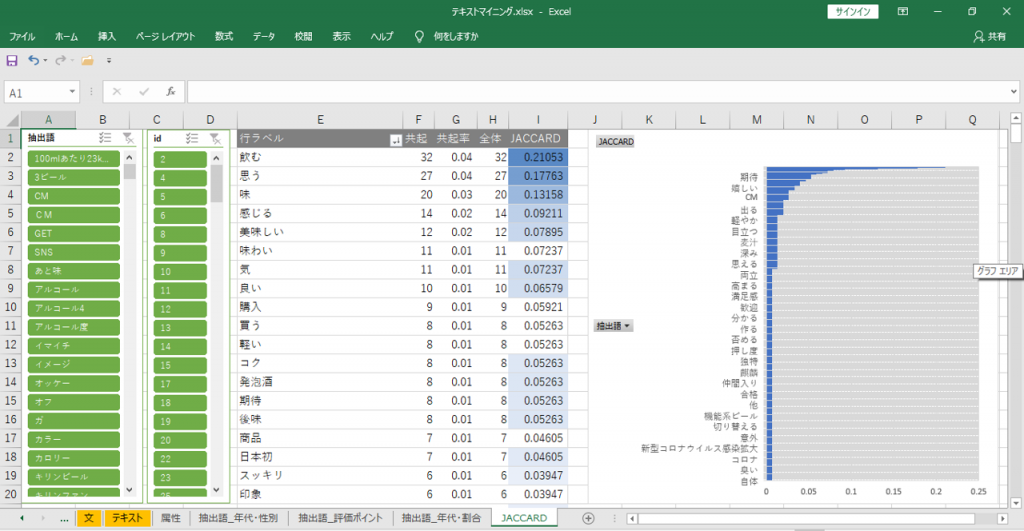
JACCARDを見るためにはフィルター操作でちょっとコツが必要です。
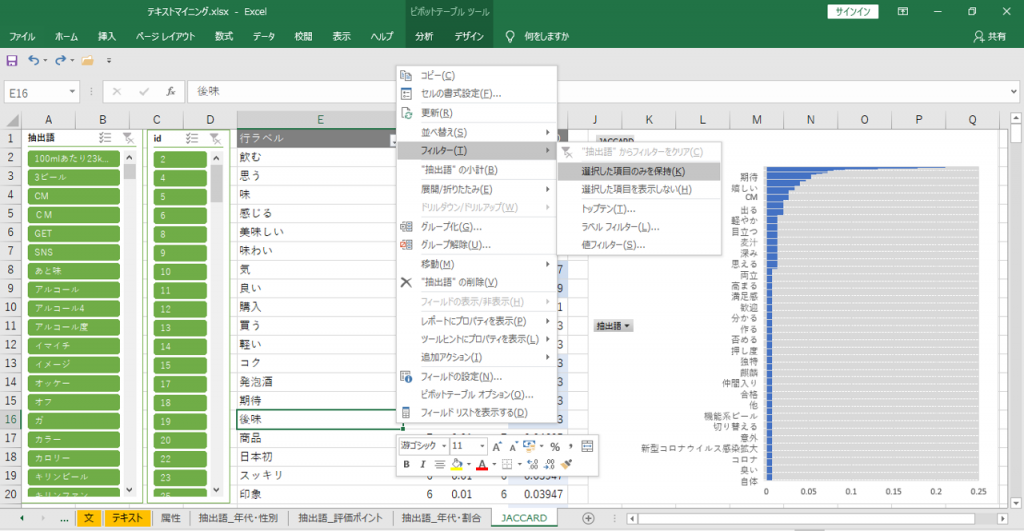
「語」を選択します。
・スライサーから選択
・ピボットテーブルから選択
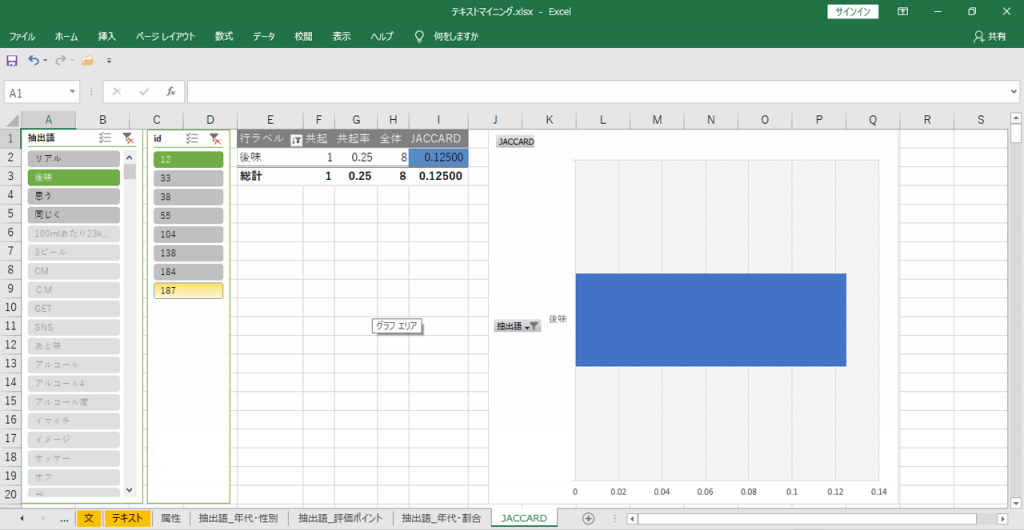
「id (語が出現する文)」が抽出されます。
・抽出された「id」をもういちど、すべて選択します。
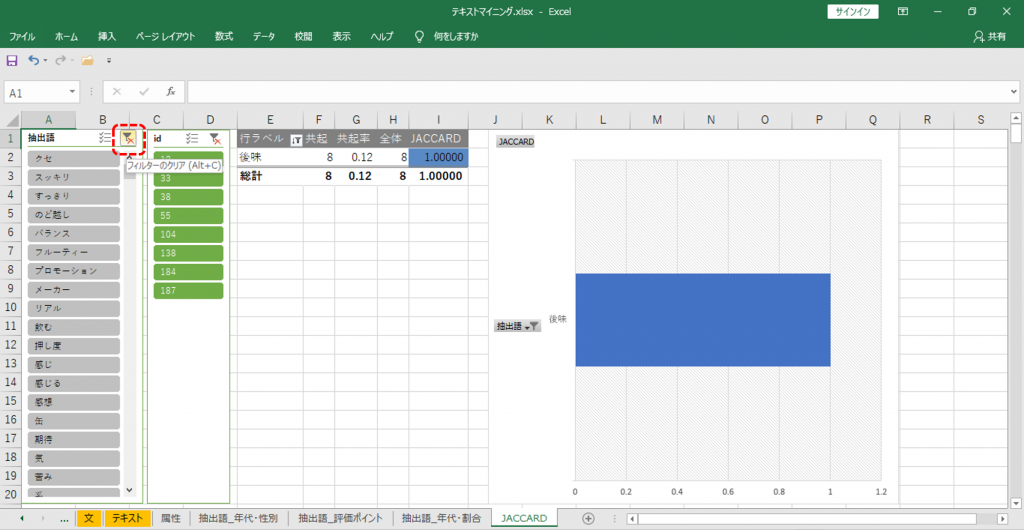
・「抽出語」のフィルターをクリアします。
これで「後味」を含む「文」にだけ出現している「語」が表示されます。
JACCCARDについてはこちらをご参照ください。
>KHcoder 12. 関連語検索(第1回) (外部リンク data-analyzer.net)
JACCARD、共起の関係が示されます。
「後味」が「軽い」、「スッキリ」していたりするみたいです。
・「共起」=選択した「語」 (後味) が出現する「文」に出現する、それぞれの「語」の出現回数。
・「全体」=それぞれの「語」が全テキストに出現する回数。
・「共起率」=「共起」÷「全体」
・JACCARD=共起÷(「全体」+選択した語 (後味) が出現する回数-「共起」)
画像の「軽い」のJACCARD計算
・分子=共起=2
・分母
「全体」=8
「後味」が出現する回数=8
「共起」=2
JACCARD=2÷(8+8-2)=0.14286