
KH coder (テキストマイニング) – データ出力 – 抽出語リスト
テキストマイニングツール KH coder から抽出語リストを出力してエクセルで見える化します。
出現回数 (TF)
出現回数 (TF) とは、分析対象テキスト全体のなかで「語」が出現する回数の集計 (合計) です。
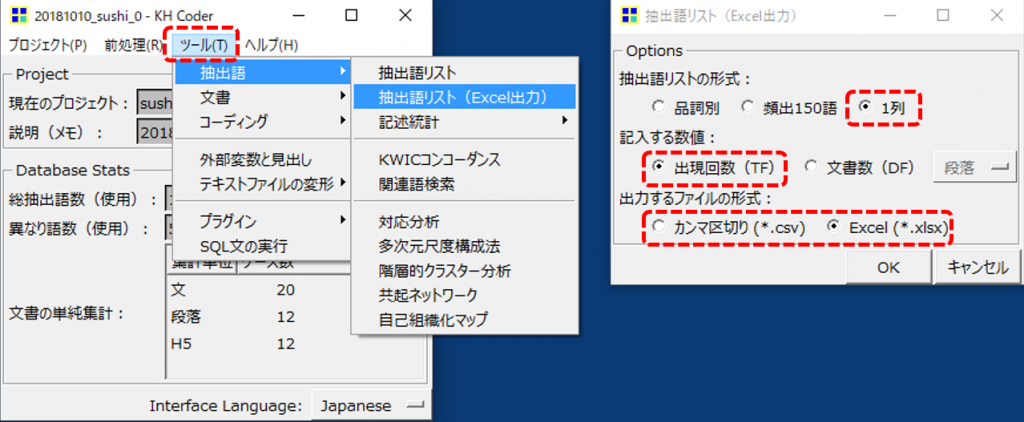
・「ツール」→「抽出語」→「抽出語リスト (Excel出力)」
出力したリストをエクセルで見える化するときには「抽出語リストの形式」で「1列」を選択します。
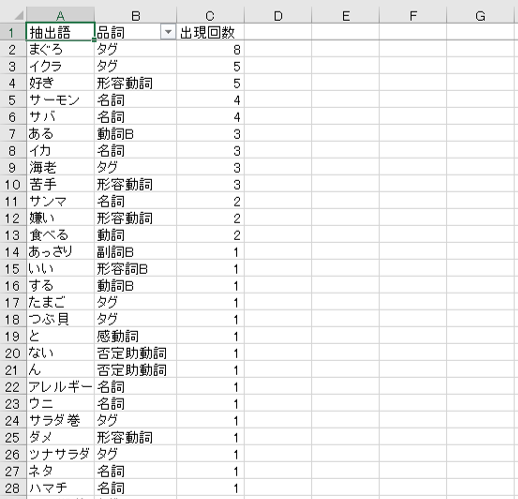
「抽出語」「品詞」「出現回数」のリストを出力できます。
A列に同一の抽出語が複数行にあらわれることがあるので注意が必要です。
<例>
良い – 形容詞
良い – 形容詞 (非自立)
同一の抽出語であっても、それぞれが別の品詞に分類されるとき複数行にあらわれます。
リレーションシップや結合するときにはダブり行を削除します。
文書数 (DF)

文書数 (DF) とは、
・「段落」に設定したときは、「抽出語」が出現する段落数
・「文」に設定したときは、「抽出語」が出現する文数
いずれも重複しない数 (Distinct) をカウントします。

「抽出語」「品詞」「文書数」のリストを出力できます。
<活用例>
アンケートの回答者数=段落数のとき、「段落」で出力した文書数=アンケートの回答者数です。
・全12名からアンケート結果を得た。
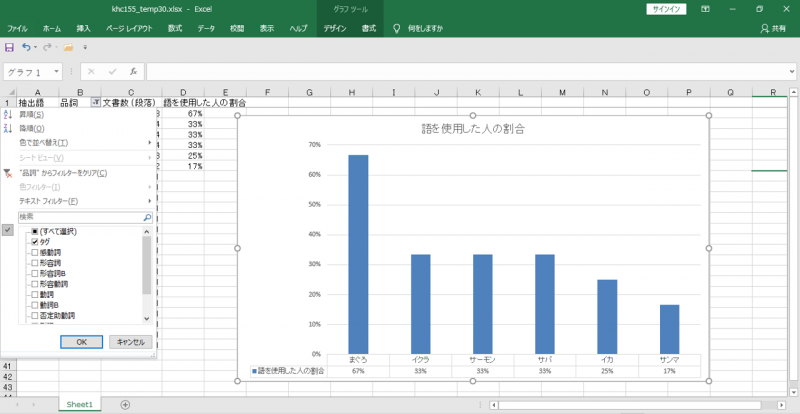
・画像のように「まぐろ」が出現する文書数は8である。
・したがって、8÷12=約67%の人が「まぐろ」という「語」を回答用紙に書き込んだ。
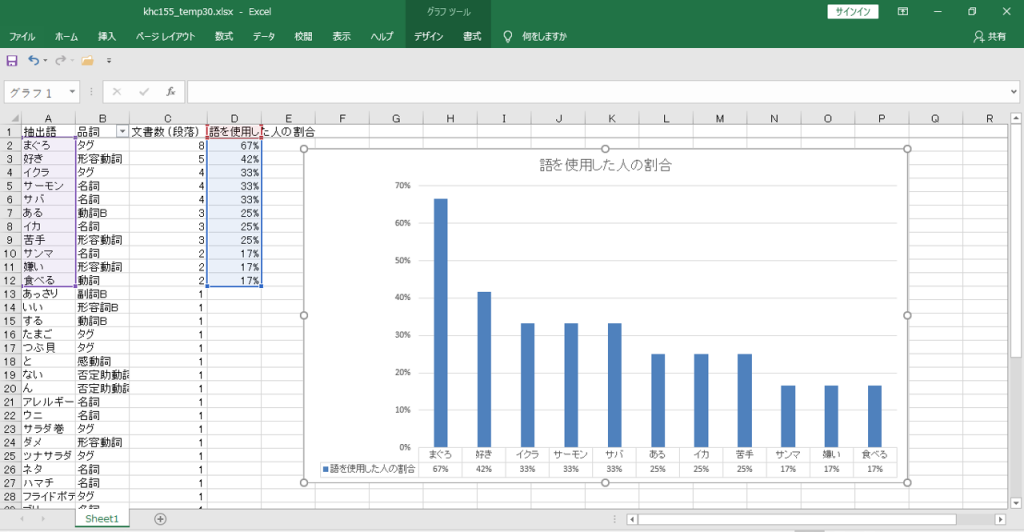
「語」を使用した人の割合を計算してグラフにします。
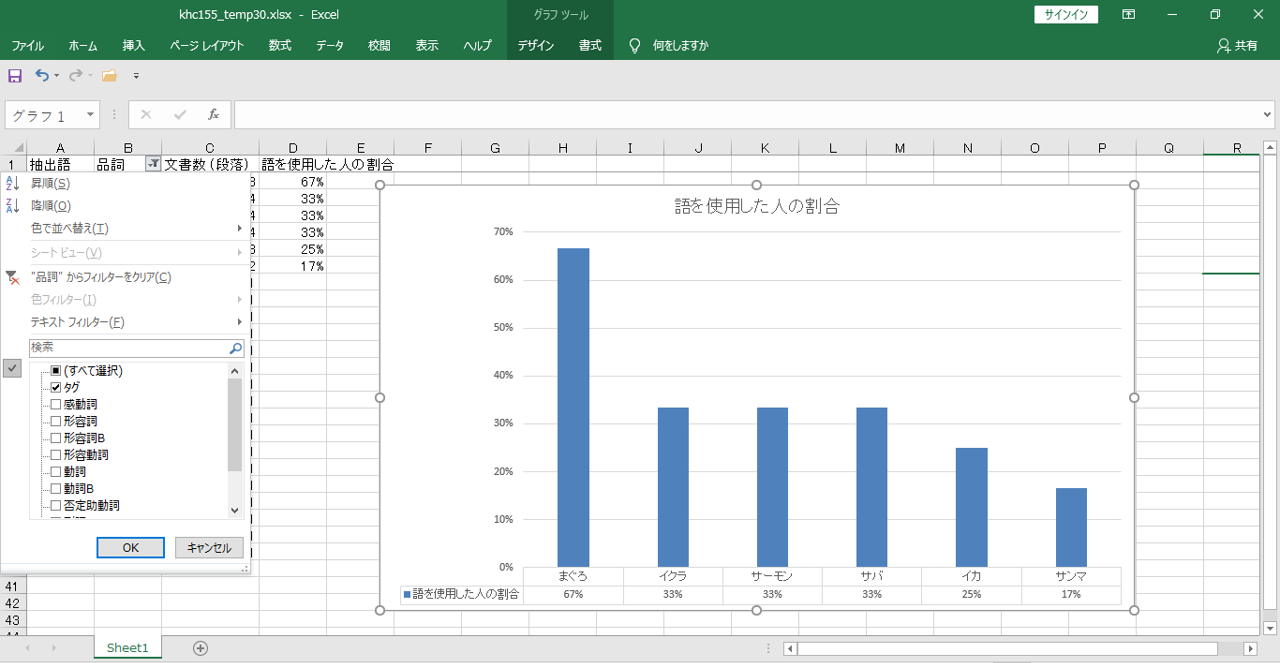
フィルターで品詞を選択します。
データ職人
データ職人