
KH coder (テキストマイニング) – データ出力 – 「文書×抽出語表」
テキストマイニングツール KH coder から「文書×抽出語表」を出力してエクセルで見える化します。
目次
出力方法
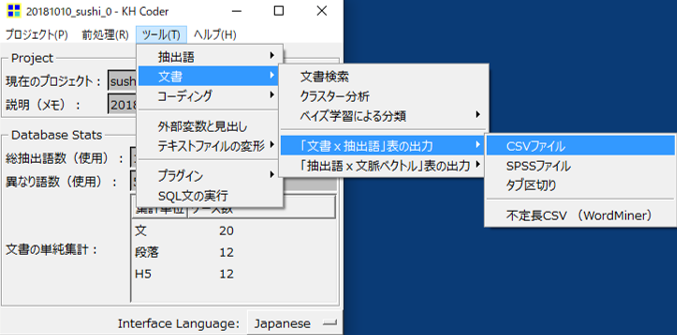
・「ツール」→「文書」→「文書×抽出語」表の出力→「CSVファイル」
(バージョンにより「プロジェクト」→「エクスポート」)
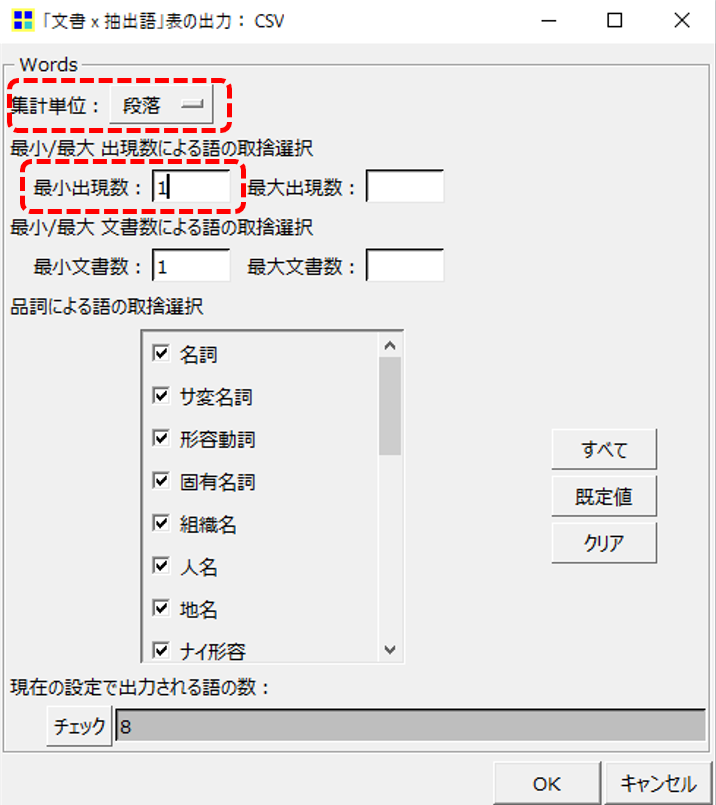
「最小出現数」の設定数値が重要です。
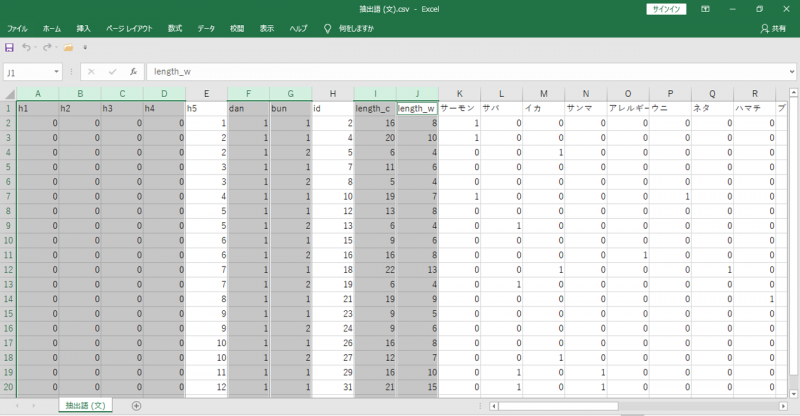
文書×抽出語表は「語」がすべて列へ (行方向) 展開されます。例えば、抽出語数が1,000になると、1,000列のCSVファイルになります。
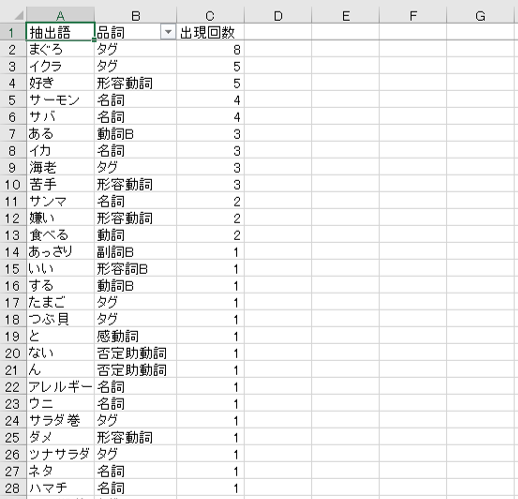
抽出語リストで出現回数が何回以上なら何語になるのかを確認してから設定します。
集計単位「段」
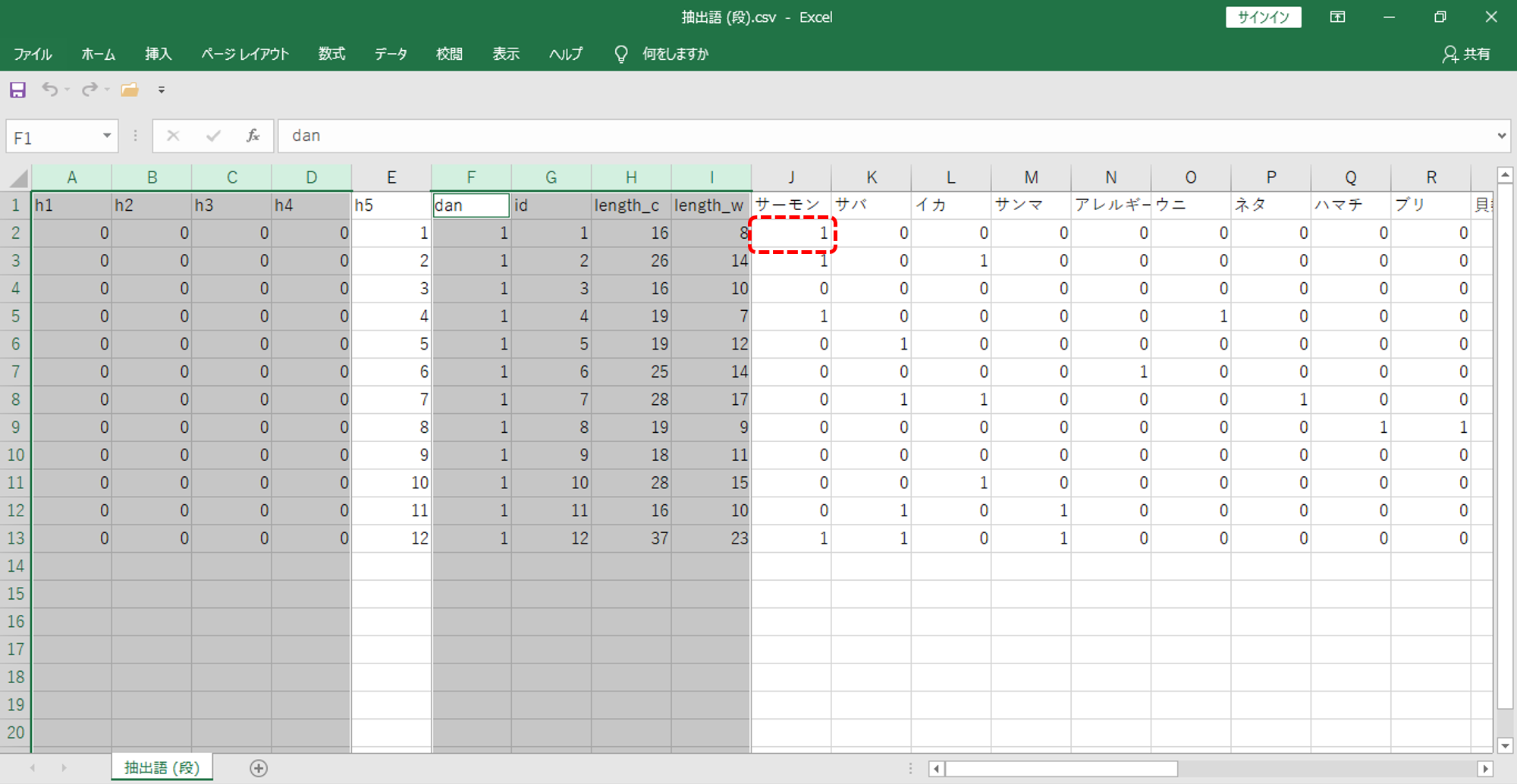
「h5」が「段」のID番号です。これはユニーク数になりダブり番号はありません。
出力結果から「h5」=1の「段」に「サーモン」という「語」が1回出現していることがわかります。
集計単位「文」
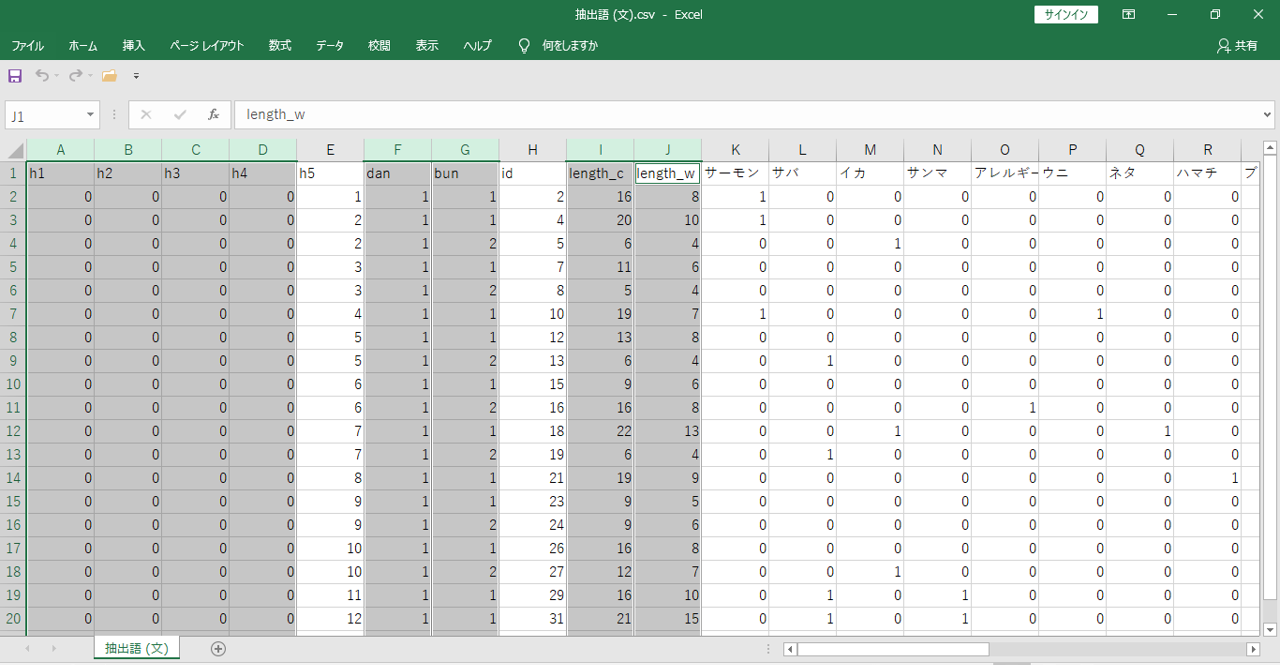
「h5」が「段」のID番号です。「id」が「文」のID番号です。「段」がさらに「文」へ分解されて、それぞれの「文」に出現する「語」をみることができます。「h5」はダブり番号あり、「id」はユニーク数になりダブり番号はありません。
集計単位「段」で出力するよりも「文」で出力すれば「段」でも「文」でも集計できるので「文」で出力するのがお得です。
活用例
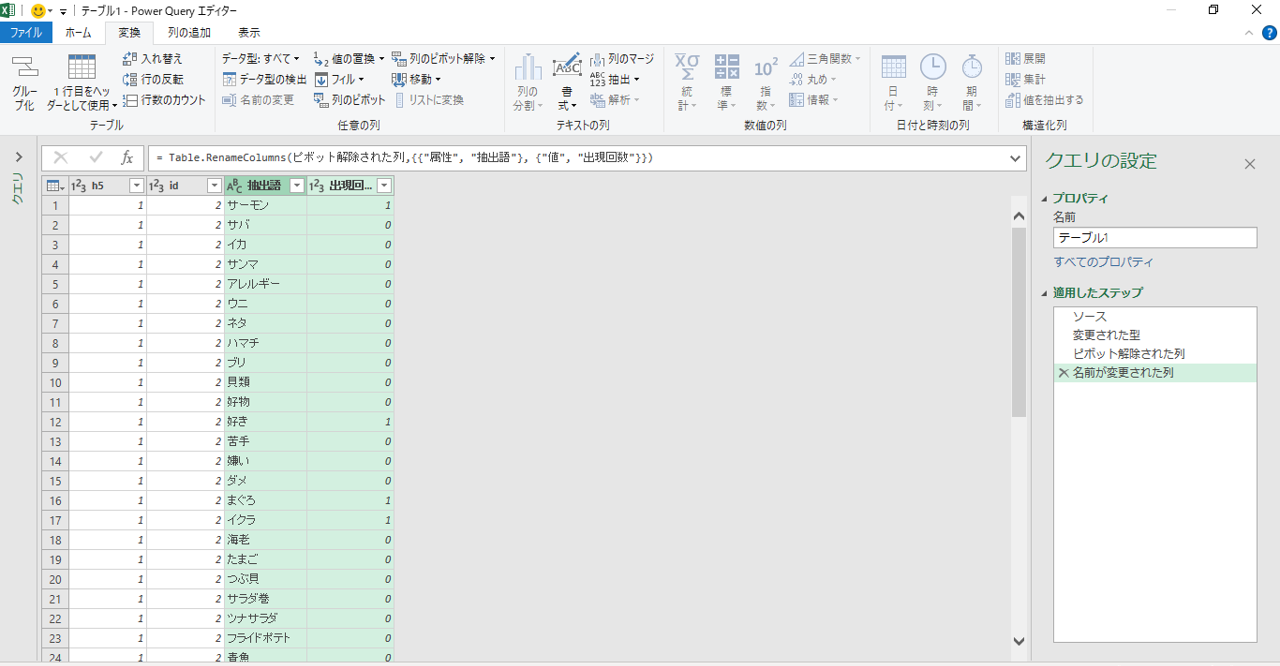
出力データはクロス集計形式です。列指向形式へ変換します。
出現階位数「ゼロ」の行はフィルターで除外します。
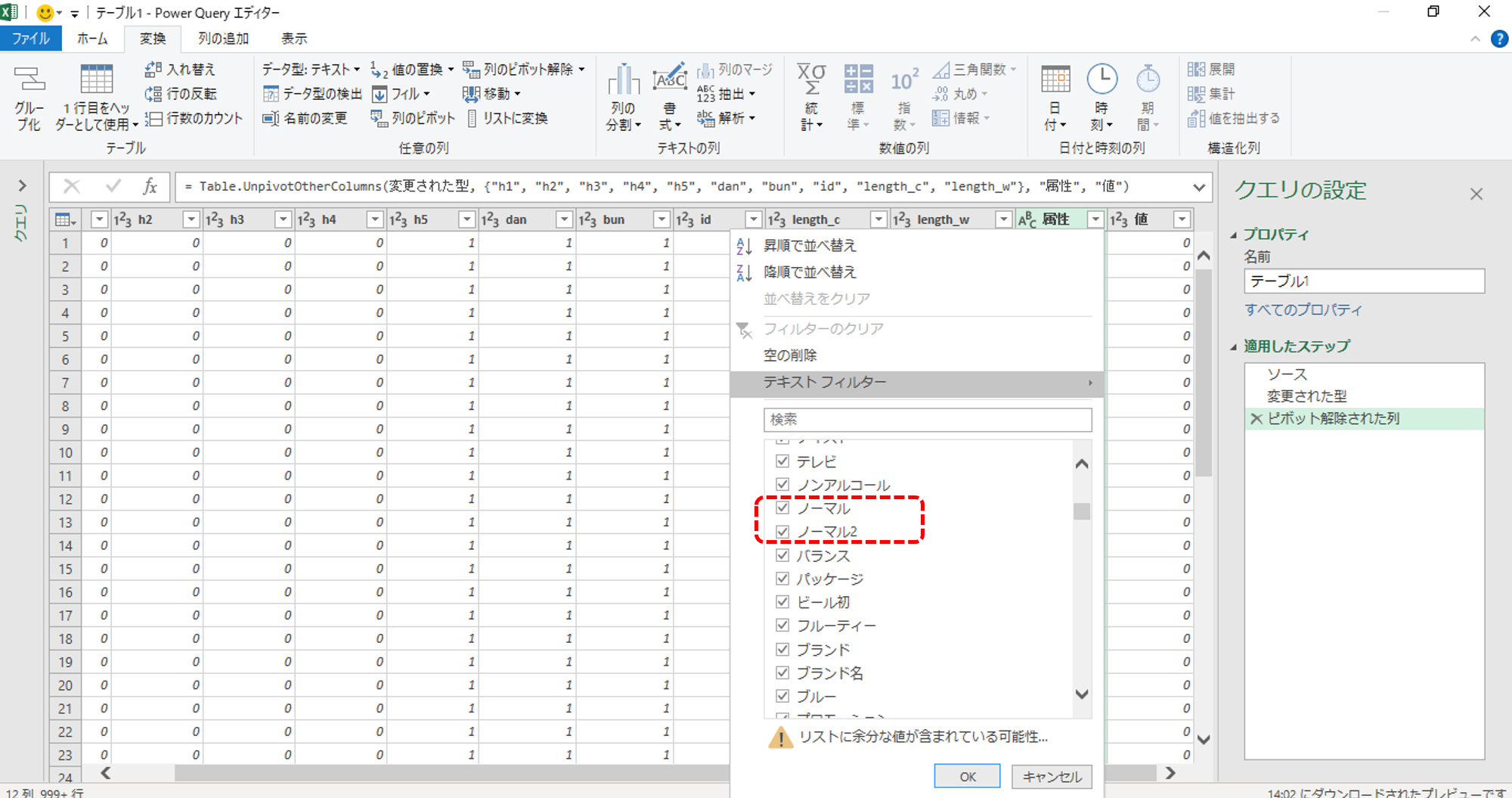
<注意ポイント>
文書×抽出語の表に同一の語が複数列にわたり出力されることがあります。ダブり列があるときに列を行へ変換すると画像のように「語」の後ろに数字が付与されます。
数字を削除して同一の語になるようにしてください。

文書×抽出語表と抽出語リストを結合して品詞をくっつけます。
外部変数とリレーションシップします。
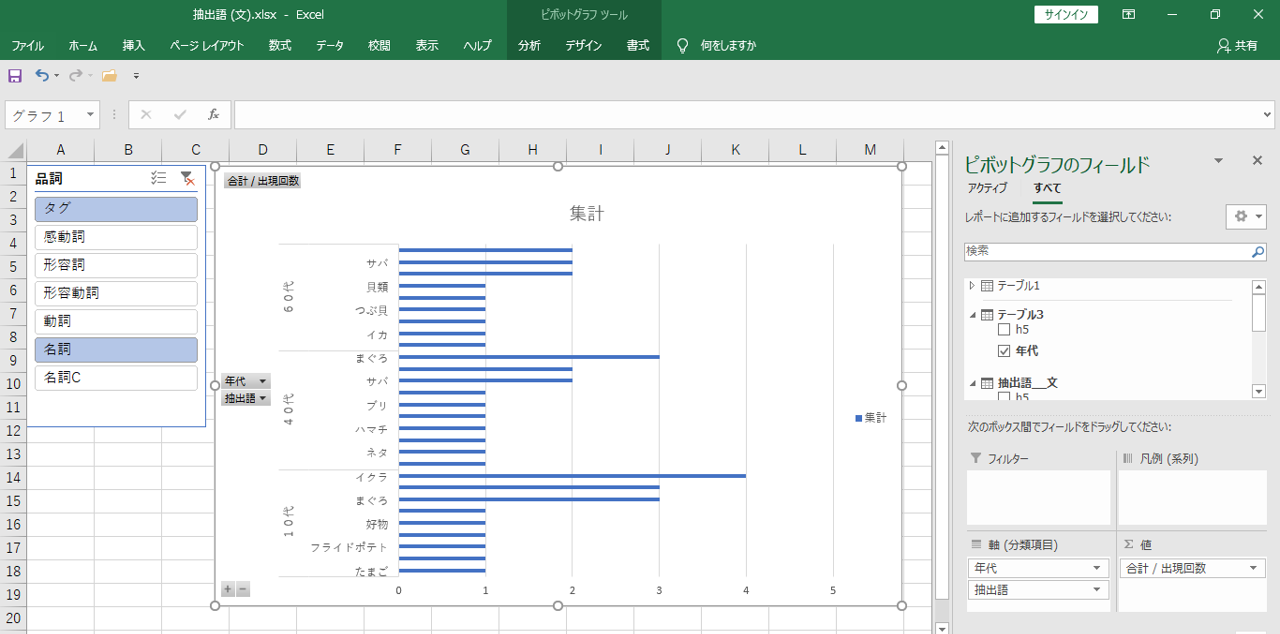
外部変数ごとに「語」が出現する回数を見える化できます。
データ職人
データ職人